
时间: 2018-12-27 10:45 浏览次数:165 来源:未知
2018金融科技发展论坛暨第三届中国金融科技创新大会”定于10月12日—13日在北京万寿宾馆召开。论坛以“新科技·新金融·新动能——推动金融科技发展,助力实体经济腾飞”为主题,届时将邀请国内外知名专家学者、金融机构负责人、金融科技企业家等嘉宾到会发表主题演讲,并于现场发布《中国金融科技发展概览》。本次论坛开展的“2018中国金融科技创新榜”案例征集活动,收到了来自金融机构和金融科技服务商提交的109个案例。
中国金融科技创新大会已成功举办两届,大会立足国内,放眼全球,聚集行业热点,已成为金融科技业界理论研究、趋势探讨、案例推介、成果分享、应用指导和业务对接的交流平台,对于推动我国金融科技的理论研究和业务创新有着积极意义。
以下为浙江农信参评案例展示:
一、案例背景
传统的银行在满足数据分析功能需求方面的服务模式,一般都是基于传统数据仓库的方式,先是一线业务人员提出需求,数据需求到分行后,经过审核,如果可以自行解决则自行解决,如果分行无法自行解决则需要提交到总行,总行从全口径对数据进行加工处理,将加工处理后的结果反馈下去。
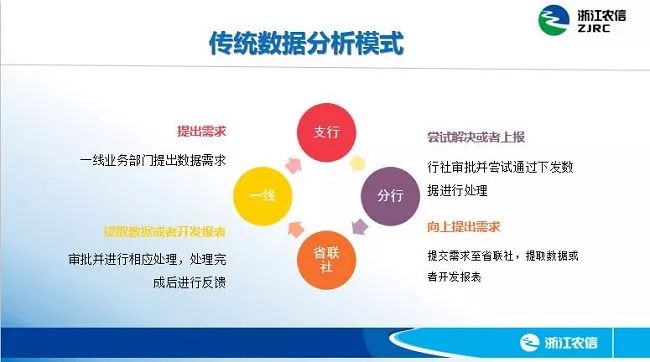
这个流程处理没有考虑到业务需求是无穷无尽的,而且是海量的、急迫的,同时真正能做数据分析的工作人员十分紧缺,这两点构成了非常突出的矛盾:
一是周期长,将结果开发成报表或者形成数据下发反馈后,已经失去了数据的实效性,无法快速响应业务部门的需求;二是业务需求与取数隔离,常常出现取数后发现无法满足需求需要重新处理的情况。
另一方面,行内已经构建了传统的报表系统,传统报表系统以制式报表为主,无法支持交互性分析,且受众具有局限性,以管理人员为主,无法做到面向全系统所有层级业务和技术人员。
二、平台特色
浙江农信针对数据分析中的业务痛点,提出了数据自助分析平台项目,旨在打造一个支持一线业务营销人员自己能够变成数据专家,能够在平台上将需要的数据查询出来,而且能够辨别数据,去做相关的数据分析。

(一)支持多主题数据自助分析功能,通过搭建一套数据指标体系,主题包括但不限于客户分析、产品分析、账户分析、渠道分析、风险分析等,在此基础上支持业务部门自助的数据分析、数据提取、数据补录;支持各层级员工按数据权限自助、快速、简单通过拖拉拽方式进行数据查询、分析和生成指标报表及展示。
(二)支持可视化报表展现,支持柱状图、层次图、关系图等多种类数据和报表展示工具,同时可以自助生成贴合实际业务需求的汇总性数据仪表盘;支持考察指标与指标的关联行分析,指标和图标钻取(即从省联社向下钻取至办事处、总行,从总行钻取至分行、支行、客户经理)。
(三)智能化、可共享、学习型的分析平台,平台支持通过对数据、指标、报表模型的查询、使用、收藏、评论等多维度的频率,进行排行,对真正有价值的数据分析模型(而非数据)实现全省共享;平台上同时也会建设学习中心、帮助中心、指标智库等模块,实现全省范围内的学习和交流。
三、解决方案描述
(一)系统架构
平台业务架构主要分为三层,包括展示层(hoop平台)、数据分析层(永洪BI)和大数据层(星环数据仓库),通过Hoop平台调用永洪BI,永洪BI向星环数据仓库请求数据,将返回的数据在永洪BI进行解析展示,由hoop平台转发展示BI平台,最后由浏览器对图形进行渲染。
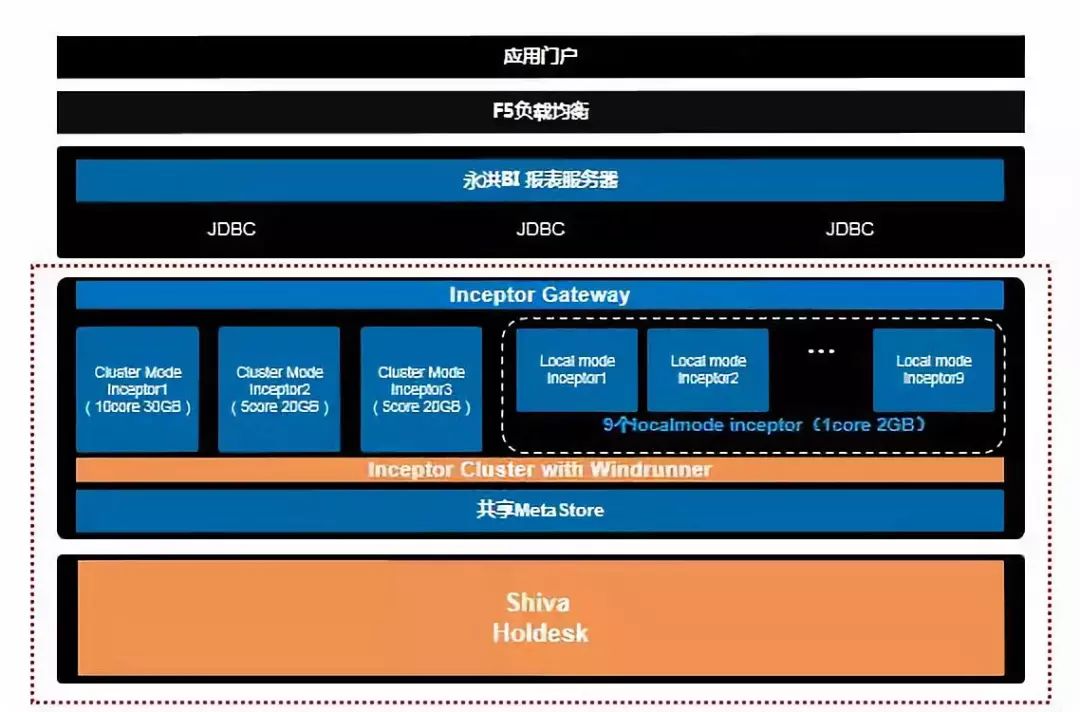
如上图所示,在整个架构中,大数据为红色虚线部分。整体架构流程为,前端提供查询请求,通过应用服务器进行负载均衡,请求提交到报表服务器后,报表工具通过标准的JDBC访问大数据平台的数据库连接。
在大数据平台内,对于接收到的查询请求首先经过gateway处理,gateway主要有三个作用:第一根据各个inceptor server的繁忙情况,进行server内的负载均衡;其次可根据server的在线情况进行服务的高可靠保障;最后当某个查询请求执行失败后,gateway根据请求返回码,会再其余的server上重新提交查询请求,保证查询任务得到响应。
目前大数据平台对外提供低延时高并发的查询响应主要是通过server端的横向扩展达到,借助于大数据平台高效的数据处理能力,以及横向扩展能力,大数据平台可以理论上可以做到无限横向扩展,已达到系统并发的要求。
下一层为元数据,不同的inceptor server共享同一份元数据,保证数据流转的便捷与高效。最底层为数据存储,目前存储在Holodesk的数据主要分为原始数据、cube数据,借助于Holodesk存储引擎的高IO特性,使得报表的查询请求,能够快速返回,满足当前系统的高并发要求。
(二)数据流转

如上图所示,本次项目依赖的数据源为数据仓库,计划每天晚上从数据同步所需数据,根据业务提供的业务逻辑首先建立OLAP cube所需的数据模型,对固定查询场景加工出所需的各项指标,自助分析主要根据提供的数据模型进行自助的数据探索。目前前端对外提供的查询主要分为两种,一种是固定查询,一种是自助分析。
1、固定查询,其查询逻辑已经确定,在大数据层面借助星环OLAP cube工具,把所有会查询的场景采用预计算的方式,物化其查询结果供前端直接调用,如图中蓝色线条所示,对于固定场景的查询请求只会访问cube中的数据,直接获取其查询结果,无须在后台实时计算,其次能够大大提高其查询效率,增加系统的并发。
2、自助分析对业务而言,开放了其能够查询的范围,支持业务人员根据自己的设想,任意维度的对数据进行探索,如上图红色线条所示,在自助分析场景中大数据后台会对提交的查询请求分析,该查询是否能够命中cube,如果能命中cube则直接从cube中取已有的结果,而无须再在后台实时的计算结果;如果无法命中cube,则需要在后台适时进行相关计算。对于这类查询无法固定其查询逻辑,需要实时在后台运行前端业务人员提交的请求,因此在响应效率方面无法与固定查询相比拟,但是也能保证在一定的性能范围内,其优势是查询的开放性以及灵活性。
(三)数据加速
OLAP(联机分析处理)是一种多维分析技术,帮助业务人员快速、交互的从多方面了解并观察数据,从而深度掌握其中的信息。OLAP采用了多维视图Cube的概念去描述一个数据集的结构。数据集中字段按照对于决策所起的作用被分为维度和度量两类:维度是描述事实记录的特征属性,相当于立方体中的坐标轴,例如时间、位置,度量是对事实记录反映出的数据,数值字段的统称,相当于在坐标中的位置,例如销售额、产量、人口。
OLAP从维度变换出发,提供钻取、切片切块、旋转等操作。钻取是对维度不同粒度不同层次(高层次到低层次,低层次到高层次)的分析;切片切块是选取特定的维度,在限定的维度中执行分析;旋转是对维度方向的变换。决策人员可以通过这些操作,从原始数据中提炼出的反映企业运作情况的直观易懂的数据,从而对决策提供支持。
随着时间推移,企业内积累的数据量的不断增长,面对日益增长的数据量,基于传统关系型数据库的OLAP分析不堪重负,其多维分析的响应时间被不断延长,因此迫切需要提供有效的方案去缩短大数据量下在线联机分析应用的的时延。由于大数据技术的发展使得数据平台的计算能力以及容量都得到相当可观的提升,基于大数据构建的数据平台可以有效应对TB甚至PB级的分析需求,其加速原理如下图所示:
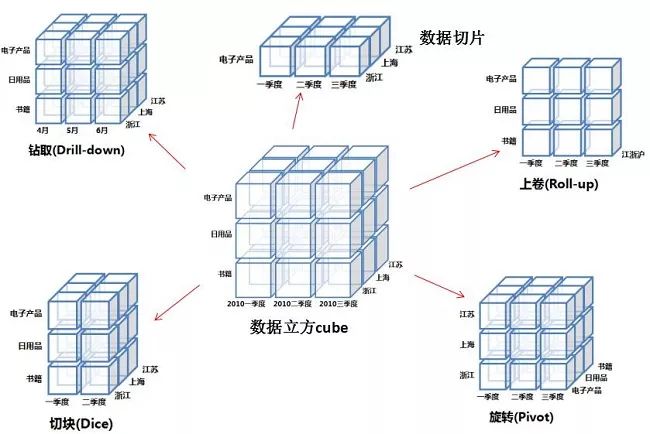
TDH提供的解决手段是根据用户预先设计好的数据立方Cube,提前进行聚合运算,将不同维度下的数据指标预存在不同的cube中,后续业务人员执行OLAP分析时可直接利用已经预计算好的结果,无需后台再实时计算,从而提速多维实时分析。该OLAP工具支持的常用操作如上卷、下钻、切片、切块、旋转等,也就是采用了用空间换取时间的策略。Tranwarp Data Hub(TDH) 5.0起提供了Rubik工具来实现OLAP Cube的设计以及管理。
四、平台功能介绍
(一)数据分析:根据需求选择不同的数据主题数据,制作相对应的分析报表,使业务人员更快速的对业务做深入分析。
(二)报表展示:分制式报表和分析报表,制式报表属于纯表格类,而分析报表属于图形类,如下图
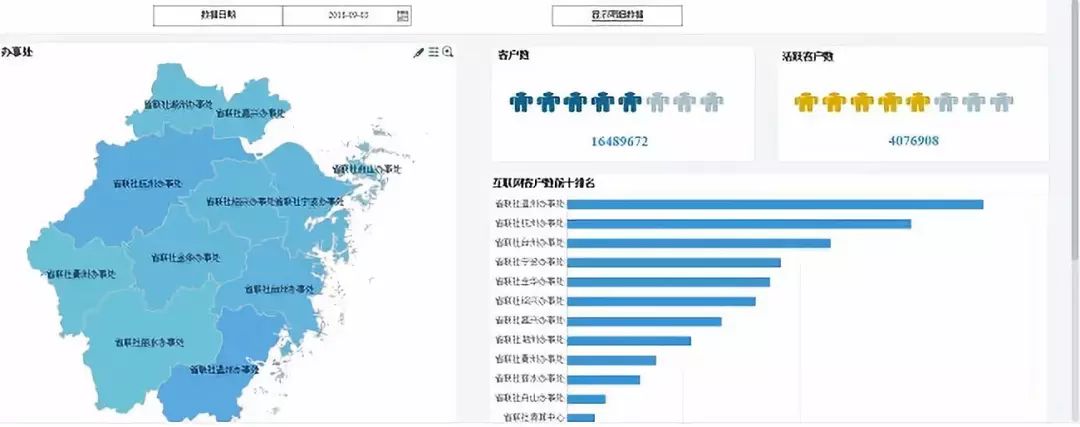
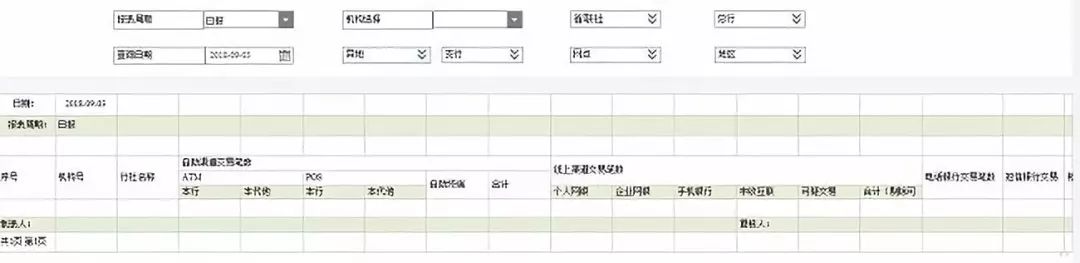
同时报表还可以进行导出、收藏、订阅、点赞,对于订阅的报表会根据订阅的周期定时推送订阅信息,提醒订阅人及时查看报表数据
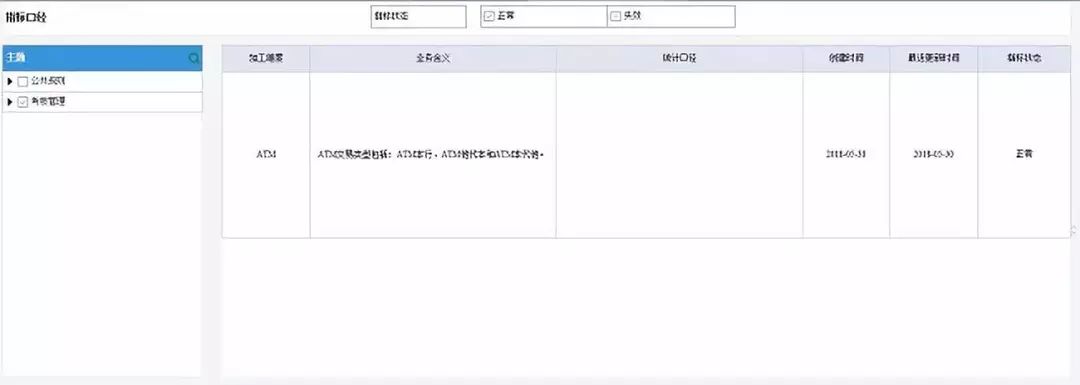
(三)指标口径查询:根据指标名称查找对应的口径,以及计算方法
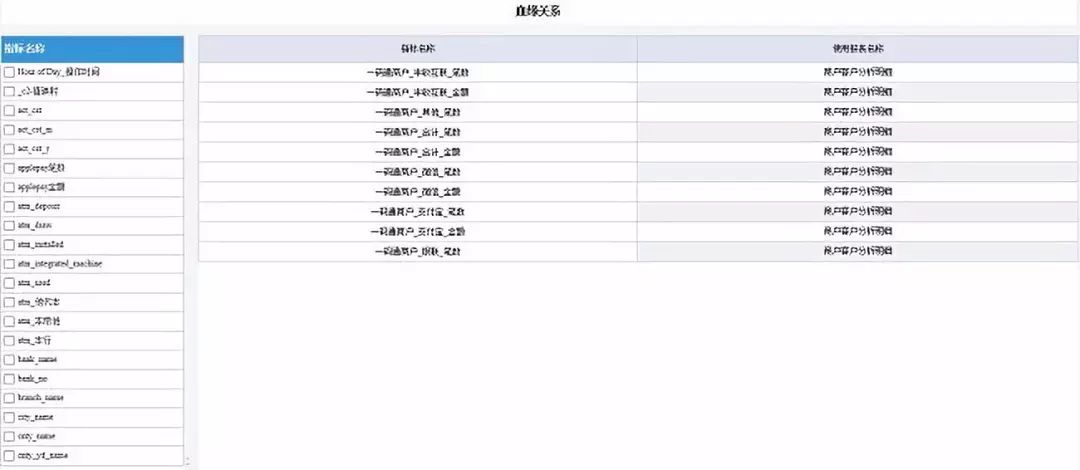
(四)血缘分析:根据单个指标查找指标所用到的报表
(五)影响性分析:根据报表名称查找报表中用到的指标名称
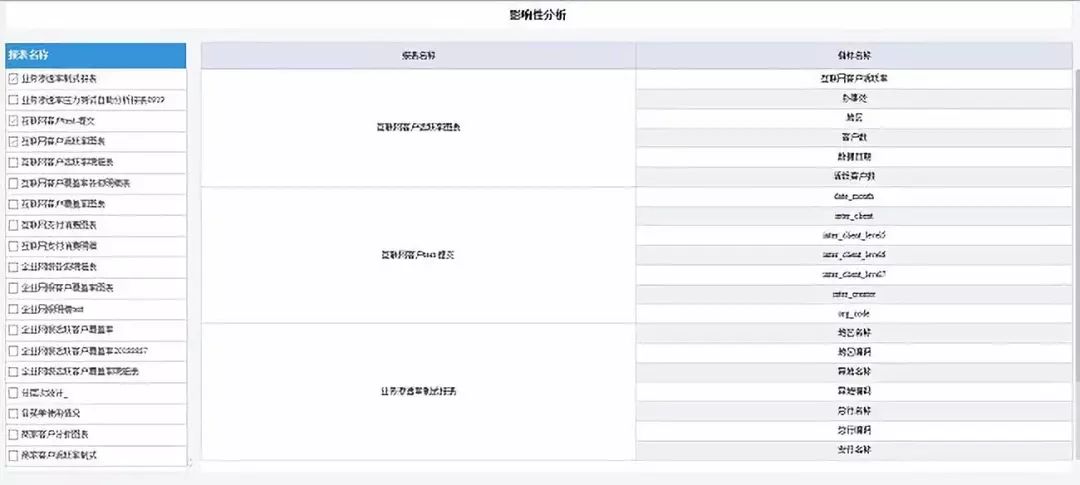
(六)报表排行:访问、评论、收藏、点赞多维度的排名、同时还增加了综合排名,根据前面的小类排名进行加权统计得到综合排名。

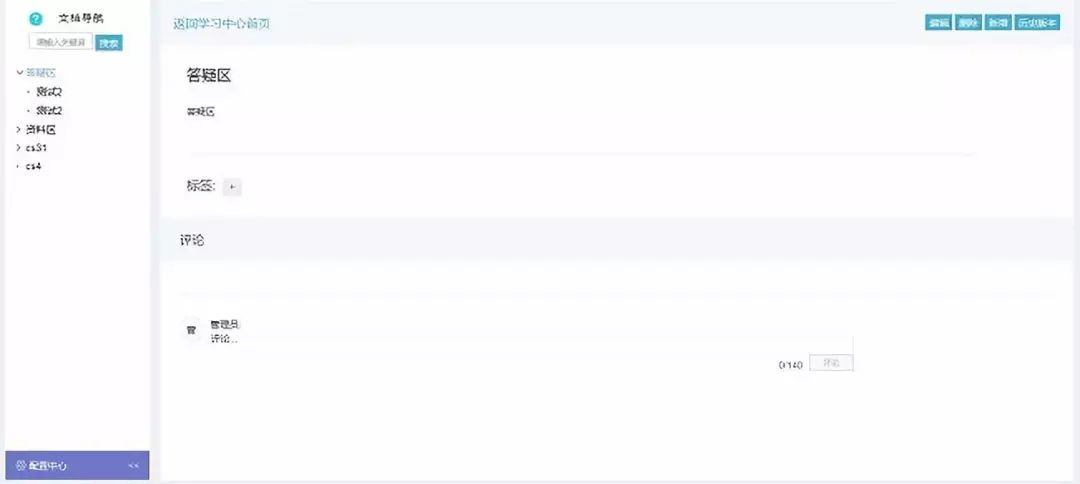
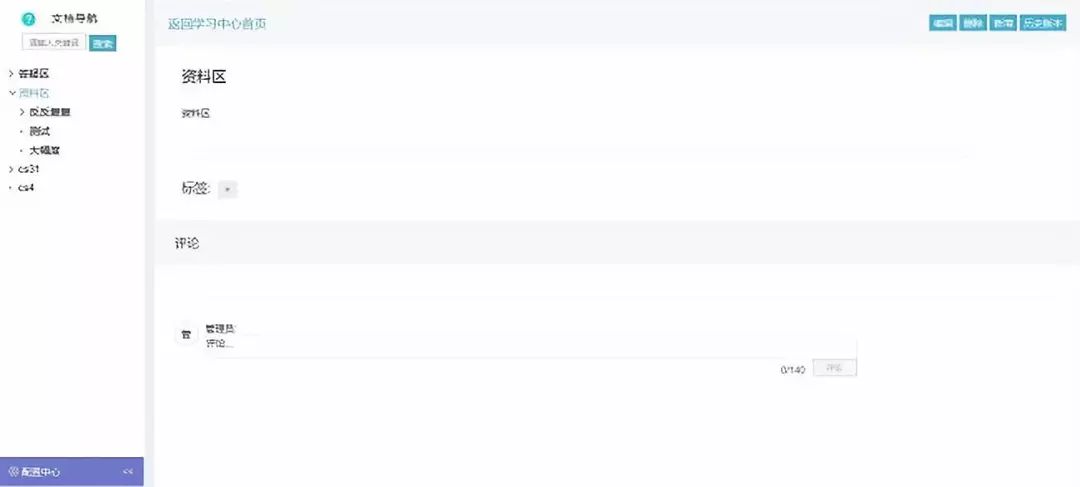
(七)学习中心:分为资料区和答疑区,资料区可进行文件的上传以及下载功能,答疑区可进行提问,评论后可进行解答,并对敏感词汇进行过滤。
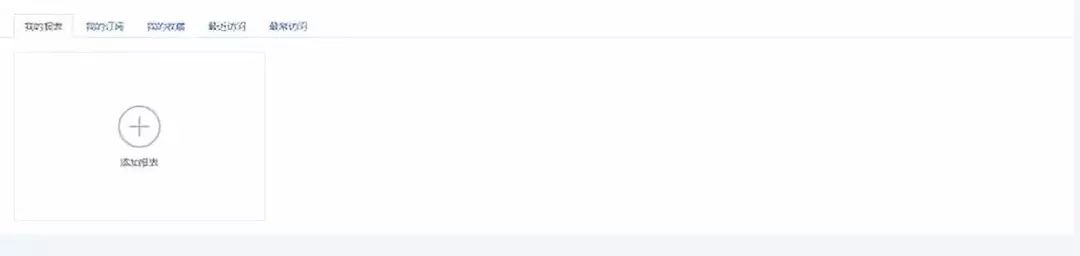
(八)个人中心:记录当前登录人员的制作、订阅、收藏、最近访问、最常访问的报表
(九)系统管理:管理员用户可对用户、角色、菜单、日志以及公告进行管理;
(十)用户管理:可以对用户账号以及角色赋予进行管理。
