
时间: 2018-11-26 12:03 浏览次数:119 来源:未知
以下为锦州银行参评案例展示:
一、大数据智能风控体系建设背景
为满足人民银行、银监会等监管部门对金融机构关于信息安全、风险交易监控、反洗钱等方面的监管要求,同时有效防范金融欺诈、盗刷、伪卡交易、套现、虚假注册、撞库等风险,我行2017年构建了大数据智能中央风控体系。大数据之后能风控体系具备事前、事中、事后的风险侦测、识别、实时干预处理能力,能够在不降低客户体验满意度的前提下实现对线上业务快速、动态风险防控。
二、大数据智能风控体系介绍
1、风控系统监控范围
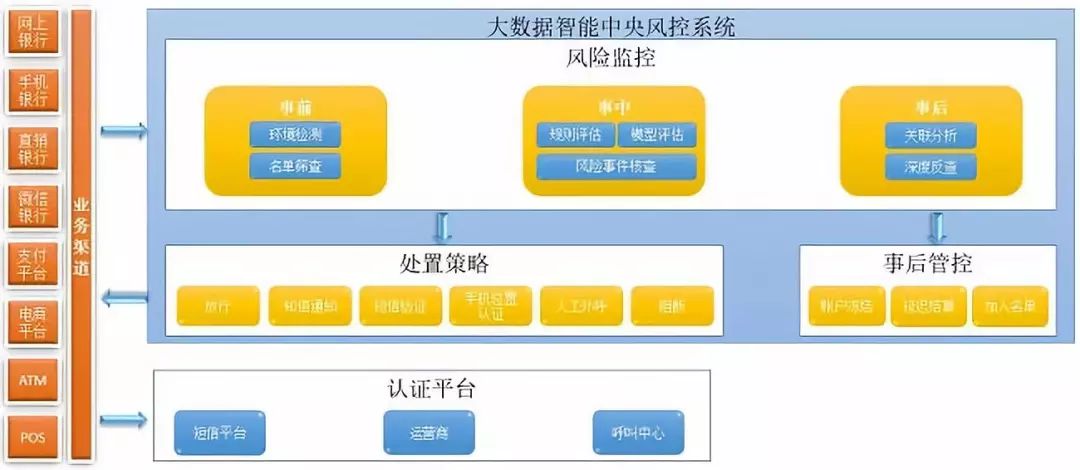
大数据智能中央风控系统,覆盖了我行各电子银行业务渠道,包括网上银行、手机银行、微信银行、直销银行、支付平台、电商平台、ATM、POS,实现了全渠道风险联防联控,监控业务覆盖各渠道重点业务交易,包括注册、登录、关键信息修改、转账、缴费充值、取现、消费等。
2、风控系统核心功能介绍
大数据智能中央风控系统采用先进的J2EE 技术规范, 采用B/S三层结构,结合分布式的软件设计思想,采用平台化设计,保证应用的可扩展和灵活部署,包含专业的规则管理平台、后台管理系统,将系统功能进行了合理的切分,能实现应用的快速部署及二次开发。该系统完全符合健壮高效的要求,具有快速的响应速度和良好的并发支持能力;同时支持应用服务器集群模式,实现服务动态分配、负载均衡。
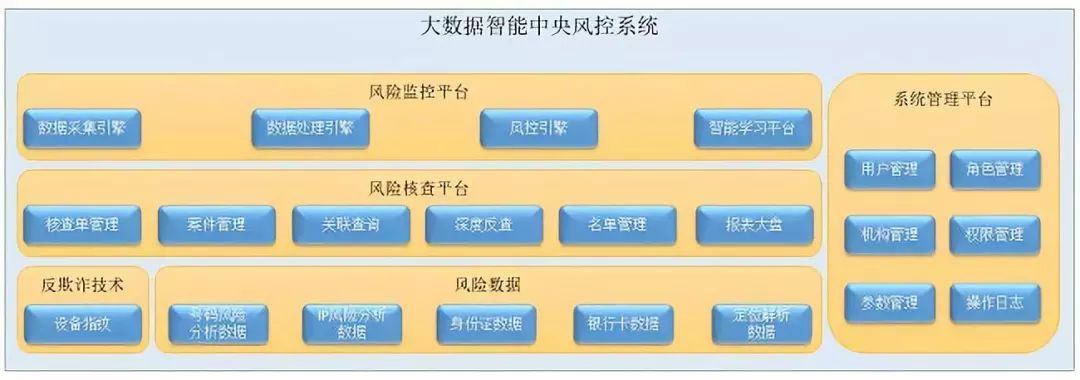
大数据智能中央风控系统基于大数据流式处理引擎和风控双引擎,确保交易的实时快速,全面的风险识别及监控。同时,大数据智能风控系统基于智能学习平台的实现规则、模型自学习、优化,能够有效减少人工优化的主观误判。
3、大数据流式处理引擎
现有的大数据处理系统可以分为两类:批处理大数据系统与流处理大数据系统。
以Hadoop为代表的批处理大数据系统需先将数据汇聚成批,经批量预处理后加载至分析型数据仓库中,以进行高性能实时查询。这类系统虽然可对完整大数据集实现高效的即席查询,但无法查询到最新的实时数据,存在数据迟滞高等问题。相较于批处理大数据系统,以Spark Streaming、Storm、Flink为代表的流处理大数据系统将实时数据通过流处理,逐条加载至高性能内存数据库中进行查询。此类系统可以对最新实时数据实现高效预设分析处理模型的查询,数据迟滞低。然而受限于内存容量,系统需丢弃原始历史数据,无法在完整大数据集上支持Ad-Hoc查询分析处理。
我行构建的大数据风控体系采用了深度融合批处理和流处理的系统级方案,攻克了以下几个难点:
(1)复杂指标的增量计算
尽管计数、求和、平均等指标能够依靠查询结果合并实现,然而方差、标准差、熵等大部分复杂指标无法依靠简单合并完成查询结果的融合。再者,当查询涉及热点数据维度及长周期时间窗口的复杂指标时,多次重新计算会带来巨大的计算开销。
(2)基于分布式内存的并行计算
采用粗放的调度策略(例如约定在每天的固定时间将流数据导入批处理系统)会造成内存资源的极大浪费,亟须研究实现一种细粒度的基于进度实时感知的融合存储策略,以极大地优化和提升融合系统的内存使用效率。
(3)多尺度时间窗口漂移的动态数据处理
来自业务系统的数据查询请求会涉及多种尺度的时间窗口,如“最近5笔刷卡交易的金额”“最近10 min内密码重试次数”“过去10年的月均交易额”等。每次查询请求都重新计算结果会对系统性能造成极大的影响,亟须研究实现一种支持多种时间窗口尺度(数秒到数十年)、多种窗口漂移方式(数据驱动、系统时钟驱动)的动态数据实时处理方法,以快速响应来自业务系统的即席查询请求。
(4)高可用、高可扩展的内存计算
基于内存介质能够大大提升数据分析及处理能力,然而由于其易挥发的特性,一般需要采用多副本的方式来实现基于内存的高可用方案,这使得“如何确保不同副本的一致性”成为一个待解决的问题。此外,在集群内存不足或者部分节点失效时,“如何让集群在不间断提供服务的同时重新平衡”同样是一个待解决的技术难题。亟须研究分布式多副本一致性协议以及自平衡的智能分区算法,以进一步提升流处理集群的可用性以及可扩展性。
大数据流式处理引擎在上述领域取得了一系列突破,该引擎提供基于时间窗口漂移的动态数据快速处理,支持计数、求和、平均、最大、最小、方差、标准差、K阶中心矩、递增/递减、最大连续递增/递减、唯一性判别、采集、过滤等多种分布式统计计算模型,并且实现了复杂事件、上下文处理等实时分析处理模型集的高效管理技术。实现高并发、低延时,亿级业务量的实时快速处理。在进行复杂逻辑处理时,不会对引擎的吞吐量造成较大影响。
4、风控引擎
风控引擎实时接收业务渠道发送的交易数据进行风险评估,根据风险评估结果生成不同的处置策略,将处置策略返回业务渠道。实时风险评估采用规则引擎+模型引擎双引擎的方式进行评估。
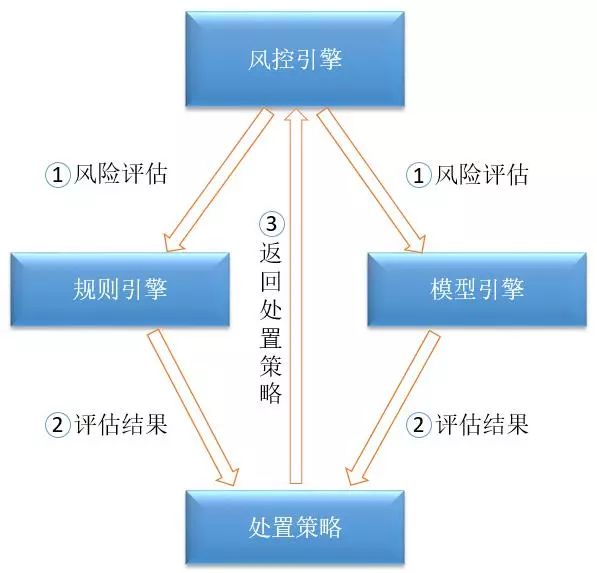
(1)规则引擎
规则引擎的核心是专家规则模型,在使用规则引擎对规则进行计算前,首先根据交易的基础变量,经过数据采集引擎进行数据变量的转换加工并扩展出用户类、会话类、设备类及位置类等规则变量,然后经过数据处理引擎的加工将客户、IP、设备、账号等统计行为类规则变量计算并扩展出来。最后将交易基础变量、预处理扩展的变量以及统计行为类变量都放入到规则引擎中,根据灵活配置的规则计算表达式,计算规则是否满足,满足则记录到命中规则列表。最后将命中的规则进行风险大小的评估。
(2)模型引擎
模型引擎的核心是机器学习模型,模型是将交易数据、签约数据、设备数据、统计数据传入到模型引擎中,使用交易模型对应的方法和具体的模型进行计算,得出风险的分值大小。该模型是一种高阶模型,相比规则模型是对问题空间做非线性区格,可以在识别欺诈交易的同时显著降低误报率;人工智能模型除了可以总结已有欺诈案件,还能够洞察潜在的欺诈模式,具有一定的对未来发生的新型欺诈的预测能力。
风控引擎的吞吐量不少于5000笔每秒,在规则数量和模型逻辑比较复杂的情况下,风控引擎的匹配吞吐量不受较大的影响。
5、智能学习平台
智能学习平台采用有监督和无监督两种机器学习模式实现规则条件、参数自动优化和模型自学习。
(1)有监督机器学习
有监督机器学习模式是反欺诈检测中最为广泛使用的机器学习模式。其中包含的学习技术分别有决策树算法,随机森林,最近邻算法,支持向量机和朴素贝叶斯分类。机器学习通常从有标签数据中自动创建出模型,来检测欺诈行为。在创建模型过程中,基于已知的欺诈黑样本,和正常的交易数据,模型中倒入的数据会影响其检测效果。用已知欺诈数据和正常数据做训练集,可以训练出学习模型来填补并增强规则引擎无法覆盖的复杂欺诈行为。
(2)无监督机器学习
无监督检测算法无需依赖于任何标签数据来训练模型。其可以通过利用关联分析和相似性分析,发现欺诈用户行为间的联系,能够不断挖掘发现新的型欺诈特征和案例,并基于特征优化完善模型,应对新兴风险;同时也为规则提供阀值及权重优化功能,降低人为主观干预所带来的误判机率。
三、风控运营效果及业务规划展望
大数据智能中央风控系统上线至今,累计监控交易2000多万笔,识别并有效拦截欺诈风险交易160笔左右,其中涉及撞库、账号盗用风险交易约120笔,账户盗刷交易约40笔,止付金额近20余万元,有效的抑制了欺诈风险交易的发生。
目前,银行业电子银行业务范围较为同质化,业务流程相似度较高。因此,减少业务流程步骤、提升客户体验将成为电子银行业务差异化发展的主流方向。为此,我行基于大数据智能风控体系,在实现电子银行风险防控的同时,将通过人工智能模型同步构建客户画像,从而进一步掌握客户行为习惯,建立客户可信体系。对于符合客户习惯并且在可信环境下的操作,尽量减少客户业务操作认证步聚,提升客户操作体验。为此我行计划分为两个阶段进行手机银行体验升级改造,第一阶段实现账户信息查询免登录,如账户收支明细、账户余额查询等操作。第二阶段实现小额动账免密操作,如扫码支付、常用收款人转账; 账户信息查询免登录、小额动账免密基于客户画像对客户有深一步的了解,同时在客户操作上对于符合客户习惯时间、习惯交易金额、可信设备、常驻地区等多维度进行综合认定,确保在客户操作无风险的前提下实现免登录或免密操作。
综上所述,在央行及银保监会等监管机构的要求及号召下,通过构建大数据智能风控体系,我行电子银行业务风险的防控能力将进一步日趋完善,从而确保我行电子银行业务的合规运营,同时为我行客户营造了更为安全可信、体验性更好的业务办理环境。
